1. Installing Hadoop - If you don't have Hadoop installed on your machine, you can follow the steps listed in my post to set up a pseudo-distributed cluster on a single machine. You will also need to make sure HBase is setup on your machine to utilize hdfs. This post walks through steps to set up HBase in a pseudo distributed mode utilizing hdfs.
2. Installing R - If you don't already have R set up on your machine, you can follow steps in this post to set R up.
or
3. Upgrading R - If you don't have the latest version of R on your machine, it may be a good idea to upgrade it by following these steps.
Next we set up RHadoop. Overall steps are as follows..
1. Configuring R shell environment to access Hadoop
2. Configuring R library paths
3. Installing R libraries
3. Installing R libraries
We will go these steps in the following post.
1. Configuring R shell environment to access Hadoop
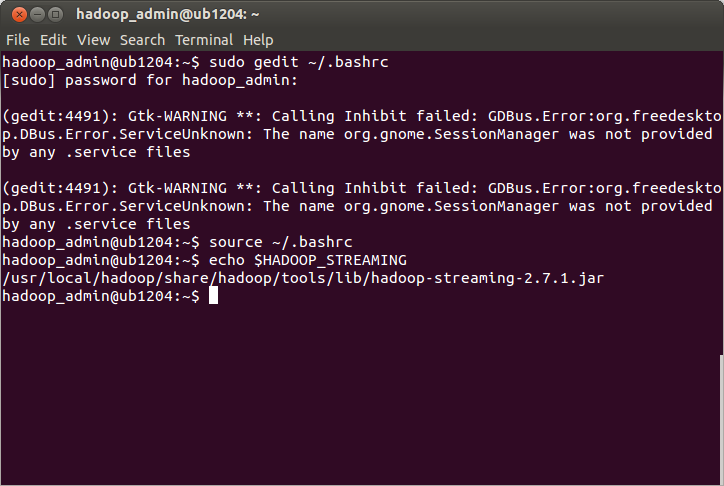
The first step is to add some configuration to the bashrc environment.Lets open the configuration file.
$ sudo ~/.bashrc

Next, add the following lines to the end of the file
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_CMD=$HADOOP_HOME/bin/hadoop
export HADOOP_STREAMING=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar

Next step is to apply these environment settings and see if the environment variables have been setup
$ source ~/.bashrc
$ echo $HADOOP_STREAMING
2. Configuring R library paths
Next step is to make sure that the library path is setup correctly, so that any installed packages will be available to all users. Start R and enter the following command$ sudo R
> .libPaths()
Make sure the paths point to /usr/local or similar, else re-configure the paths to point to these folders, by setting a destination path in the install command. On my machine, I did not have to change anything.

Next, we need to download the needed packages from the RHadoop site.
I created a folder called rhadoop on my local account and downloaded the following packages from github using the wget command
wget http://cran.r-project.org/src/contrib/rJava_0.9-6.tar.gz
wget https://github.com/RevolutionAnalytics/rmr2/releases/download/3.3.1/rmr2_3.3.1.tar.gz
wget https://github.com/RevolutionAnalytics/rhdfs/blob/master/build/rhdfs_1.0.8.tar.gz?raw=true
wget https://github.com/RevolutionAnalytics/rhbase/blob/master/build/rhbase_1.2.1.tar.gz?raw=true
wget https://github.com/RevolutionAnalytics/ravro/blob/1.0.4/build/ravro_1.0.4.tar.gz?raw=true
wget https://github.com/RevolutionAnalytics/plyrmr/releases/download/0.6.0/plyrmr_0.6.0.tar.gz
mv rhdfs_1.0.8.tar.gz\?raw\=true rhdfs_1.0.8.tar.gz
mv rhbase_1.2.1.tar.gz\?raw\=true rhbase_1.2.1.tar.gz
mv ravro_1.0.4.tar.gz\?raw\=true ravro_1.0.4.tar.gz

Next we need to update the JDK
$ sudo R CMD javareconf

Next, we will install rJava package that we downloaded
$ sudo R
install.packages("~/rhadoop/rJava_0.9-6.tar.gz", repos=NULL, type="source")
Next step is to install some pre-requisite R packages
> install.packages(c("Rcpp", "RJSONIO", "bitops", "digest", "functional", "stringr", "plyr", "reshape2", "dplyr", "R.methodsS3", "caTools", "Hmisc"))

> install.packages("data.table")

Next we will deploy these packages in R. Enter the following commands on the R command prompt.
Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/bin/hadoop")
install.packages("~/rhadoop/rmr2_3.3.1.tar.gz", repos=NULL, type="source")
install.packages("~/rhadoop/rhdfs_1.0.8.tar.gz", repos=NULL, type="source")
install.packages("~/rhadoop/plyrmr_0.6.0.tar.gz", repos=NULL, type="source")
install.packages("~/rhadoop/rhbase_1.2.1.tar.gz", repos=NULL, type="source")
install.packages("~/rhadoop/ravro_1.0.4.tar.gz", repos=NULL, type="source")

That's it rhadoop is installed. To make sure everything is working, start R in normal mode and issue the following commands
> Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/bin/hadoop")
> library(rmr2)
> library(rhdfs)
> hdfs.init()

Now the R environment is ready to use the HDFS environment.
No comments:
Post a Comment