In this post, we are going to load some
shape file data into PostGIS. Loading Shape file data into PostGIS involves two steps. These are:
1. Convert Shape file to SQL Insert statements
2. Execute the SQL Insert statements on a PostGIS instance.
Let us start with the first step.
PostGIS ships with a tool for converting shape files to SQL insert scripts for PostGIS called shp2pgsql described below.
shp2pgsql
As the name suggests, shp2pgsql
converts shape files into PostGIS compatible SQL Insert scripts. The tool
itself is deployed in a sub-folder called “loader” in the primary
installation folder. It should get built when the primary PostGIS
tool is built on your machine as part of your installation as
described in my previous post on
downloading
and installing PostGIS.
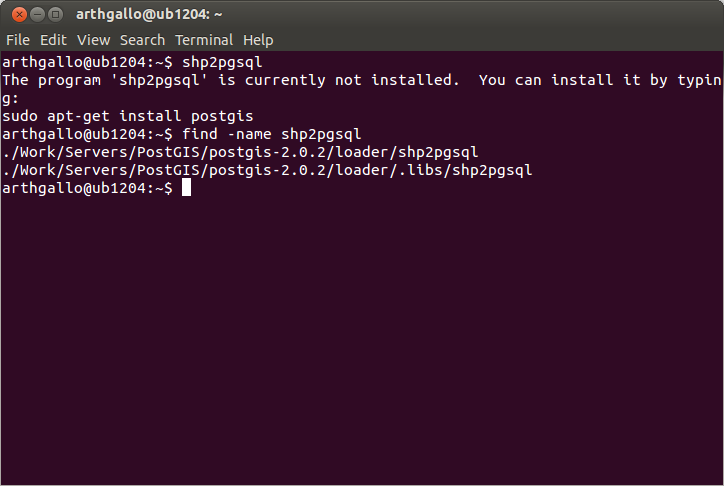
Opening a terminal window and running
the shp2pgsql command should display all the runtime options and
switches.
If you are not shown the above options,
it may be that shp2pgsql is not in your path. Adding shp2pgsql (or
any other command) to your path is easy as described in my
post
on the topic.
Let us start with an example with some real data. I am using certain publicly available datasets from New York Dept of Transportation for this exercise.
Obtaining and Loading data into PostGIS
The data consists of the following data obtained from following public sources.
I proceeded to download these files from their respective locations. Once we have downloaded all the datasets, we need to extract these files for loading on PostGIS. To achieve this I created a small script that looks as follows:
extract_GISData.sh
mkdir ../Data/GISData
unzip -o 2010_AADT_Line.zip -d ../Data/GISData
unzip -o 2010_Short_Count.zip -d ../Data/GISData
unzip -o fhwa2000.zip -d ../Data/GISData
unzip -o nyshore.zip -d ../Data/GISData
unzip -o 2010_Continuous_Count.zip -d ../Data/GISData
unzip -o DOT_MilepointRoute.zip -d ../Data/GISData
unzip -o nyintch.zip -d ../Data/GISData
My final script looks as below...
Now we need to upload these extracted shape files to PostGIS.
To execute this file, we need to make the file executable and open a terminal window to execute it using the following commands.
$ chmod a+x *.sh
$ ./extract_GISData.sh
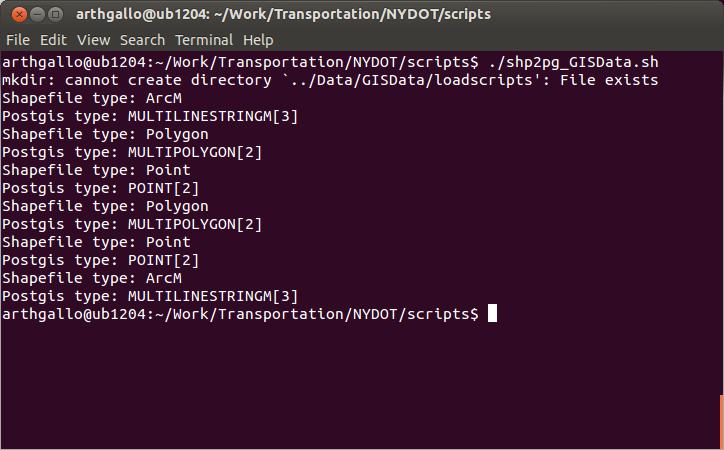
In the following screenshot, we can see the script running on my machine.
Next we need to load the extracted shape file data into the PostGIS database using the shp2pgsql utility. Let us create a script that will
process each individual file separately and create the insert scripts
from each shape file.
shp2pg_GISData.sh
rmdir
--ignore-fail-on-non-empty ../Data/GISData/loadscripts
mkdir
../Data/GISData/loadscripts
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/2010_AADT.shp
nystaging.2010_AADT>
../Data/GISData/loadscripts/insert_2010_AADT.sql
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/counties.shp
nystaging.counties>
../Data/GISData/loadscripts/insert_counties.sql
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/2010_Continuous_Count.shp
nystaging.2010_Continuous_Count >
../Data/GISData/loadscripts/insert_2010_Continuous_Count.sql
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/FHWAUrbanAreas2000.shp
nystaging.FHWAUrbanAreas2000>
../Data/GISData/loadscripts/insert_FHWAUrbanAreas2000.sql
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/2010_Short_Counts.shp
nystaging.2010_Short_Counts>
../Data/GISData/loadscripts/insert_2010_Short_Counts.sql
shp2pgsql
-s 26918 -d -I -g geom ../Data/GISData/MilepointRoute.shp
nystaging.Milepointroute>
../Data/GISData/loadscripts/insert_MilepointRoute.sql
In the above
script, -d option will dump the original table and recreate it.
Option -I will create a spatial index on the geometric column where
as -g specifies the name of the geometric column.
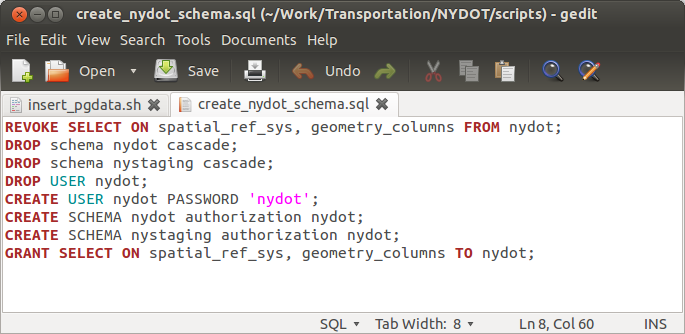
Here is my script
in the gedit editor.
Now we will save
the file and execute it. To make the file executable, we need to run
the command chmod
$
chmod a+x *.sh
$
./shp2pg_GISData.sh
Now that the
files have been created, we can upload them to PostGIS. We are of
course going to use the psql command for uploading the insert
scripts. Here are the command line switches to the psql command.
I first needed to
create a schema in a pre-existing database. To do so, I created a
script that looks like as follows.
create_nydot_schema.sql
REVOKE SELECT ON spatial_ref_sys, geometry_columns FROM nydot;
DROP schema nydot cascade;
DROP schema nystaging cascade;
DROP USER nydot;
CREATE USER nydot PASSWORD 'nydot';
CREATE SCHEMA nydot authorization nydot;
CREATE SCHEMA nystaging authorization nydot;
GRANT SELECT ON spatial_ref_sys, geometry_columns TO nydot;
Then, to execute
I needed to run it as user postgres. Here are the commands for
logging in as user postgres and executing the script:
$ su – postgres
postgres$ psql -d
nywarehouse -f
/home/arthgallo/Work/Transportation/NYDOT/scripts/create_nydot_schema.sql
Now we are ready
to execute the insertion scripts on PostGIS. We need to create a file
that will execute each if the insert scripts generated at previous
steps. As most may know, psql does not allow supplying passwords in
the command line. It has to be set in the environment variables. This
post
describes how to set the password in .pgpass file on Ubuntu/ Linux
environment.
Also, I want to
load the spatial data into the staging schema instead of the primary
warehouse schema first. To do so, I need to specify the staging
schema in the command line input parameters. This is not a standard
capability in the psql command line options, however, it is very easy
to do so, as described in my post
on specifying schema in the command line psql parameters.
Here is the
complete script for loading the files.
insert_pgdata.sh
rm
../Data/GISData/loadscripts/*.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_2010_AADT.sql -L ../Data/GISData/loadscripts/insert_2010_AADT.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_2010_Continuous_Count.sql -L ../Data/GISData/loadscripts/insert_2010_Continuous_Count.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_2010_Short_Counts.sql -L ../Data/GISData/loadscripts/insert_2010_Short_Counts.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_counties.sql -L ../Data/GISData/loadscripts/insert_counties.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_FHWAUrbanAreas2000.sql -L ../Data/GISData/loadscripts/insert_FHWAUrbanAreas2000.log
psql -U nydot -d nywarehouse -v schema=nystaging,public -f ../Data/GISData/loadscripts/insert_MilepointRoute.sql -L ../Data/GISData/loadscripts/insert_MilepointRoute.log
Here is a
screenshot of the script on my screen.
We can execute
the script using the following psql command
$
./insert_pgdata.sh
The script when
running properly shows a bunch of INSERT statements as shown below.
Now that the data
is loaded, we can view the same in uDig. If you don't have uDig installed on your machine, you can follow my post on
uDig installation to set it up. The following screen shows us accessing the newly loaded datasets in uDig.
Now, we can see
our data loaded in PostGIS.
That's it. We are done!